
在進入後續的 Serving Pipeline 環節之前,我們最後用一天討論一下 Auto ML,Auto ML 的目的是希望將整個訓練的過程,變成一個完全自動的環節,前面我們提到,在特定如風險控制的領域,駭客手法有很強的週期性,每隔一段時間就會有不同的手法,導致你的模型很容易會過一段時間就失效,比起去探索一個可以應變各種可能狀況的模型,加速模型迭代的速度可能是更好的做法,但要做到這點有兩個我們必須要小心的處理,也就是 Bias 和 Label
如何透過自動化的演算法來偵測這些 Bias 是一個需要解決的問題
目前的題目主要都是針對 Supervise 的題目,即使是 Unsupervise 的題目,Feedback Loop 也是要驗證模型不可或缺的環節,但是高質量的 Labeling Data 往往是一個很困難得到的數據,Label 大致可以分成以下幾種來源:
這裡我覺得有一個重點,真實世界的標注資料不一定能非黑即白,很多時候我會將標注至料做一個 Confidnece 程度的排序,像是專家審核,我就會給她很高的 Confidence,但是先前模型輸出,可能就會是相對低的 Confidence
即使有了這些,我們離 AutoML 還是有一定的距離,AWS 和 Google Cloud 都有提供 AutoML解決方案,H2O 和 Scikit-Learn 也都有提供開源的 AutoML 解決方案,都可以參考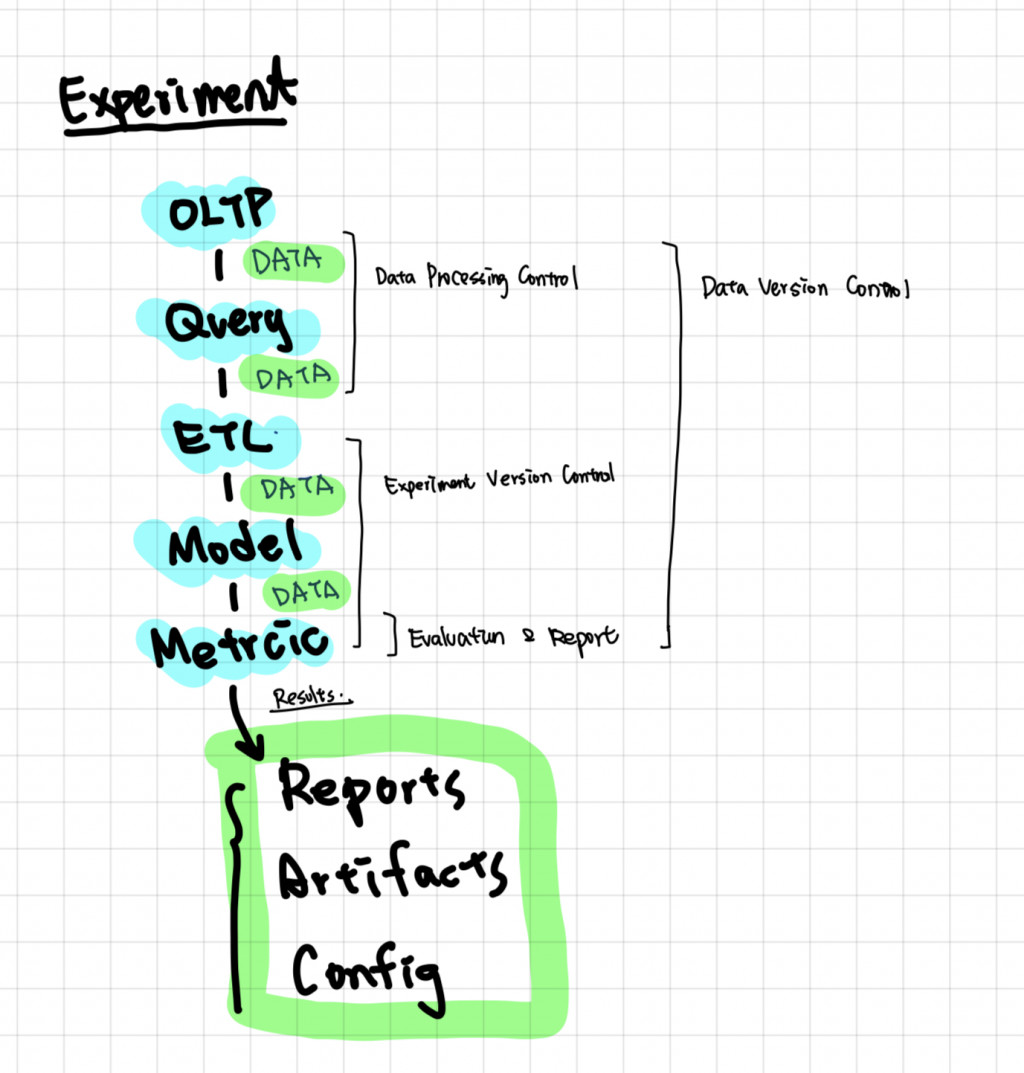
在前 13 天裡,我們將重點放在訓練/ 實驗階段,並以一個風險領域的二元分類的問題 -- Account Takeover Detection 出發,從原本一站式的 Jupyter Notebook 開發,解構出一些常用的元件,並針對一些常用的工具是為什麼目的來做介紹,並提到了一些開源工具,這些工具很多都有重疊的功能,並不一定要全部都用上,然後透過這些工具和元件就可以在實驗階段建構一個 MLOps 系統,我認為 訓練階段的MLOps 系統最終體現,就是一個 AutoML 工具,達到過去實驗所累積的知識底都可以被應用在後續的實驗之中!那就讓我們繼續往 Serving 的方向前進

 iThome鐵人賽
iThome鐵人賽